4.4 Создание классификационной модели
В данном разделе описывается процесс создания классификационной модели для анализа гиперспектральных данных на основе корректного определения целевых классов для анализа и настройки параметров, которые будут использованы для обучения. Корректно построенная модель классификации позволит, используя спектральную информацию эффективно распознавать объекты исследования.
Классификационная модель в программном обеспечении Breeze создается с целью автоматической классификации болезней сельскохозяйственных культур на основе задаваемых параметров или характеристик (признаков) заболеваний растений. В результате, модель, на основе дерева принятия решений обучается сегментации определенных участков (пораженных) растений, что позволяет создать «базу» для дальнейшего предсказания новых импортируемых данных.
Для создания классификационной модели необходимо перейти к опции «Model» на левой панели и открыть меню уже созданных моделей, где возможно создание новой (рисунок 54).
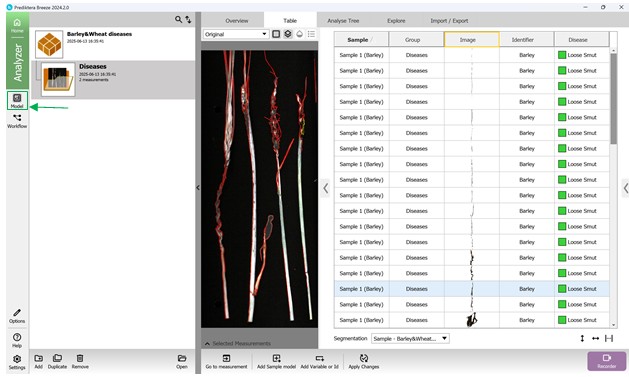
Рисунок 54 – Переход в меню моделей для добавления новой модели
Затем в левой части нижней панели осуществляется выбор кнопки «Add», в результате чего открывается мастер создания «Новой модели», где выбирается третья кнопка «Classification» и метод классификации «PLS-DA», основанный на частичных наименьших квадратах с категориальными переменными (классами) (рисунок 55).
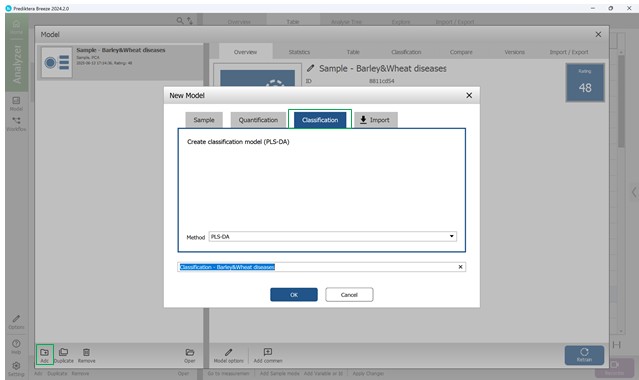
Рисунок 55 – Выбор метода классификации PLS-DA
Далее следует процесс создания самой классификационной модели, включающий:
- этап 1: выбор переменных (рисунок 56);
- этап 2: выбор образцов (участков культуры, пораженных заболеваниями) (рисунок 57);
- этап 3: выбор: диапазонов длин волн в пределах необработанного спектра отдельных пораженных участков образцов (по умолчанию обычно включаются все диапазоны длин волн) (рисунок 58), модельных нагрузок (рисунок 59), весовых коэффициентов в рамках выбранного волнового диапазона по основным компонентам (рисунок 60); просмотр: показателей значимости (рисунок 61), показателей отношения сигнал-шума в рамках выбранного волнового диапазона (рисунок 62). На этапе предварительной обработки применяется метод SNV, который расшифровывается как Standard Normal Variate correction. Использование данного метода в обработке спектроскопических данных позволяет минимизировать различия в плотности и толщине образцов, а также влияние мультипликативных эффектов рассеяния света;
- этап 4: расчет основных статистических показателей модели PLS-DA: рассмотрение параметров PC1-PC5 (рисунок 63, 64). Диаграмма в формате точечного графика под названием «Score variance» демонстрируют наличие выбросов в исследуемых выборках. График под названием «Overview» позволяет исследовать качество формируемой модели, которое отражается через такие показатели как «R2» и «Q2». Данная диаграмма отражает также информацию о количестве компонентов. Совокупные показатели «R2» и «Q2» показывают подгонку модели и вероятный прогноз на основе данных, полученных в результате перекрестной проверки, то есть показатель «R2», отражающий коэффициент детерминации, показывает, насколько хорошо модель подгоняет обучающие данные, а показатель «Q2», отражающий предсказательную способность модели, показывает, насколько именно хорошо модель может предсказывать данные, которым данная модель не была обучена раннее. Чем выше показатель – тем выше соответствующие способности автоподгонки модели. За основу могут браться полученные показатели «R2» и «Q2» того компонента, после которого не происходит их существенного увеличения (например, компонент 3) (рисунок 64). Диаграммы «Distance to model» отражают расстояние до модели по каждому отдельному набору данных образца, что позволяет оценить и выявить наличие каких-либо выбросов. Превышение определенного показателя для расстояния Х (черная линия на графике) может быть свидетельством того, что данный образец является выбросом;
- этап 5: оценка созданной модели PLS-DA осуществляется по трем основным графикам – «Observed vs. Calculated», «Overview» и «Variable overview». На графике «Observed vs. Calculated», представляющем диаграмму разделения классов по одной оси, указываются истинные значения классификации определенных образцов к конкретных классам, по другой оси предсказанные моделью значения в отношении каждого образца. График «Variable overview» демонстрирует дисперсию «R2» (насколько хорошо модель может описывать различия между классами данных, использованных для обучения) и предсказательную способность «Q2» для каждого класса (насколько хорошо модель может предсказывать определенные участки культур, пораженные заболеваниями, в процессе кросс-валидации). Далее осуществляется переход к кнопке «Finish», на чем завершается создание классификационной модели (рисунок 65).
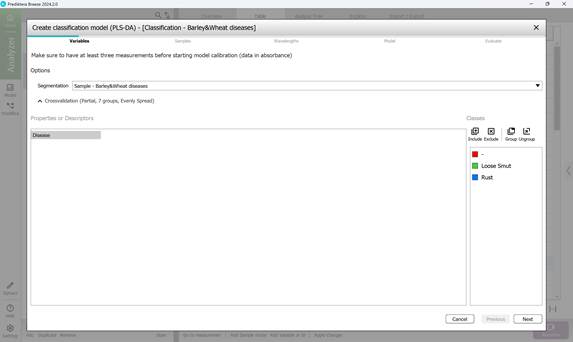
Рисунок 56 – Создание классификационной модели: выбор переменных
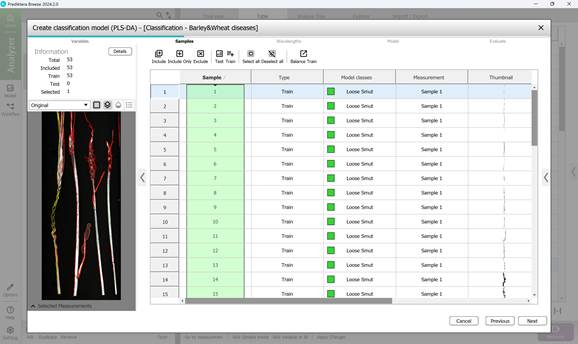
Рисунок 57 – Создание классификационной модели: выбор образцов
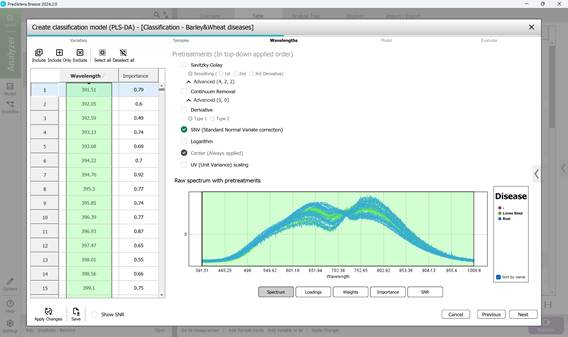
Рисунок 58 – Необработанный спектр отдельных пораженных участков образцов в рамках исследуемого волнового диапазона
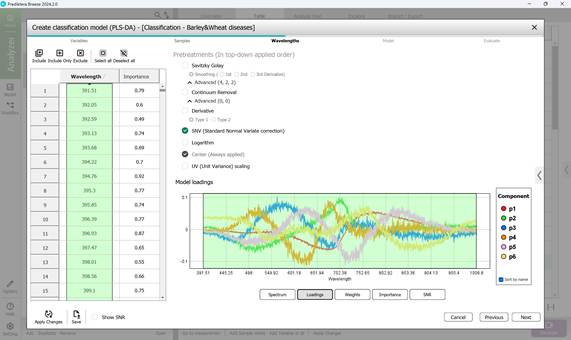
Рисунок 59 – Модельные нагрузки по основным компонентам при создании классификационной модели
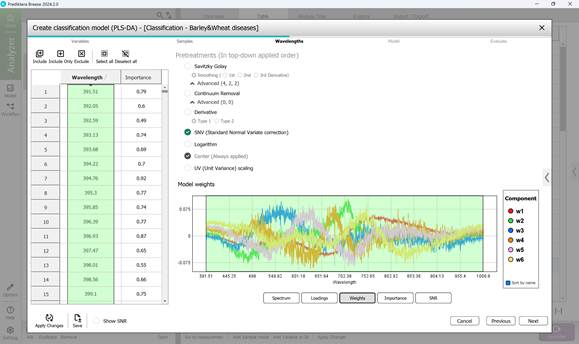
Рисунок 60 – Весовые коэффициенты по основным компонентам при создании классификационной модели
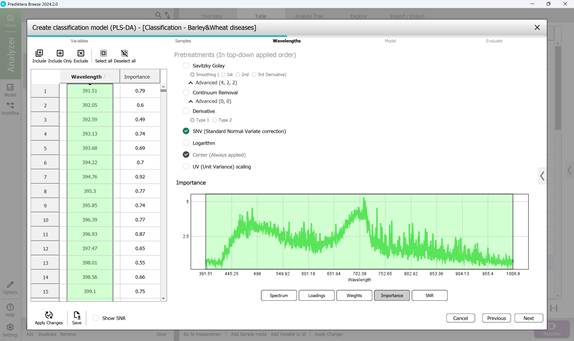
Рисунок 61 – Показатели значимости при создании классификационной модели
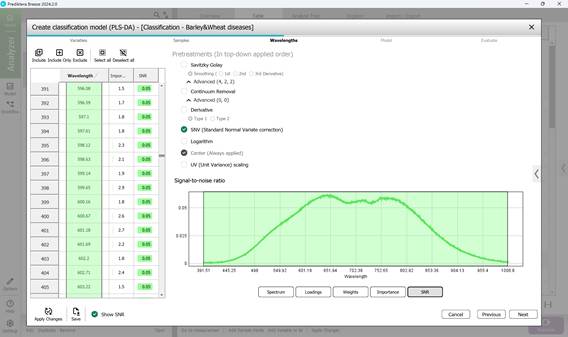
Рисунок 62 – Отношение сигнал-шума в рамках волнового диапазона при создании классификационной модели
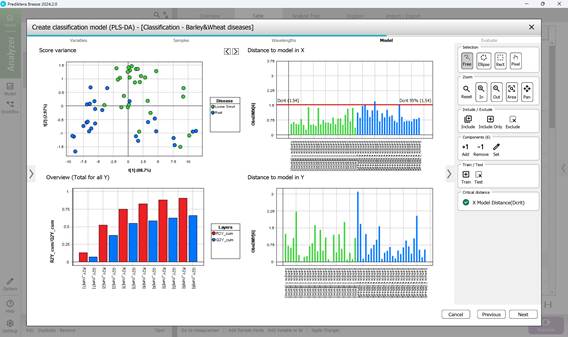
Рисунок 63 – Расчет модели PLS-DA: рассмотрение параметров PC1 и PC2
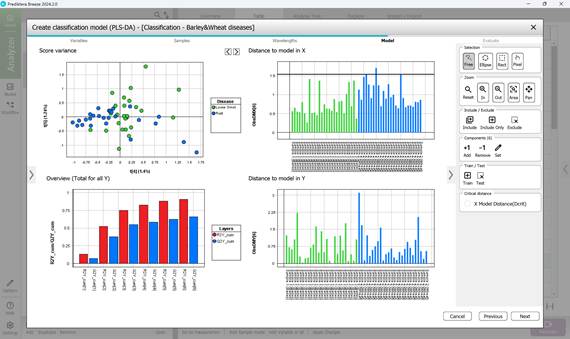
Рисунок 64 – Расчет модели PLS-DA: рассмотрение параметров PC4 и PC5
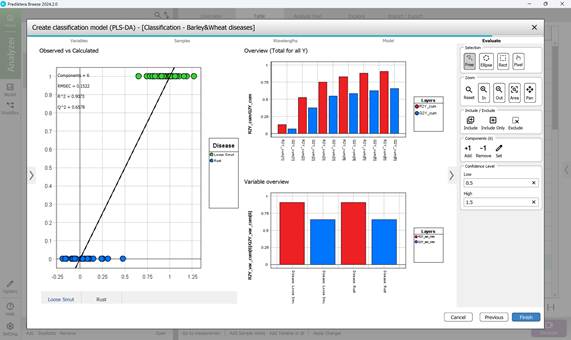
Рисунок 65 – Оценка созданной модели PLS-DA
Общую информацию о созданной модели PLS-DA, в том числе статистике, качестве предсказания и ключевых статистических метриках можно получить в меню «Model» при навигации между основными кнопками в пределах построенной классификационной модели. В разделе «Overview» содержится информация о количестве образцов, спектральных каналов, главных компонентах, волновом диапазоне, параметрах предварительной обработки, кросс-валидации, модели сегментации и др. (рисунок 66).
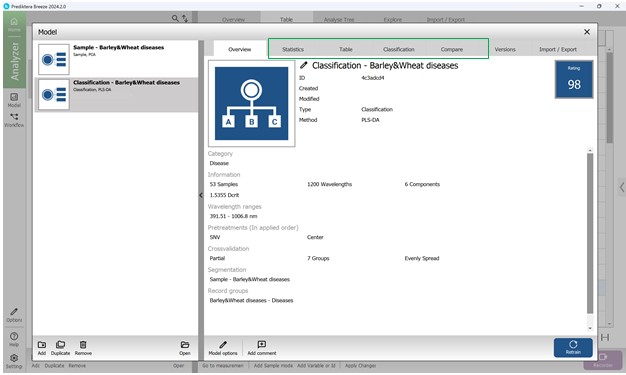
Рисунок 66 – Общая информация о созданной модели PLS-DA
Второй раздел в меню «Model» в пределах построенной PLS-DA модели содержит информацию о графической статистике. График «Score Variance» наглядно показывает на какую именно долю вариации (то есть дисперсии) приходится объяснение в пределах каждой компоненты модели. График «Observed vs. Calculated», демонстрирует разделение классов, где по одной оси указываются истинные значения классификации, а по другой оси предсказанные моделью значения для каждого отдельного образца. График «Overview» отражает качество формируемой модели через показатели «R2» и «Q2». График «Variable overview» содержит информацию о дисперсии и предсказательной способности каждого класса исследуемых признаков. График «DModX» показывает меру расстояния исследуемого образца до модели в пространстве переменных X, после проекции на модель. Чем ниже значение на данном графике, тем более лучше описан образец. Соответственно, при возникновении определенных выбросов по показателям они будут превышать пороговое значение линии доверия, то есть «critical distance», с учетом того, что доверительный интервал равен 95 % (рисунок 67). Числовое отражение всех статистических показателей указывается при переходе в третий раздел «Table» в меню «Model» (рисунок 68).
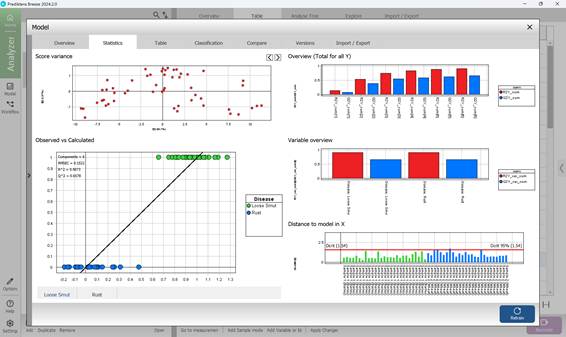
Рисунок 67 – Графическая статистика модели PLS-DA
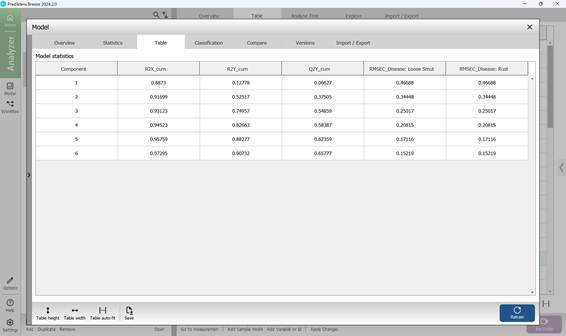
Рисунок 68 – Числовая статистика модели PLS-DA
Четвертый раздел под названием «Classification» содержит информацию о матрице ошибок (рисунок 69), где в столбцах указываются классы, по которым осуществляется классификация определяемых заболеваний сельскохозяйственных культур, а в строках указываются правильные классы для раннее заданных параметров образцов. К примеру, на рисунке 69 только один образец (1,89 %) классифицирован неверно. Для регулирования диапазона классификации исследуемых пораженных участков в пределах образцов отобранных сельскохозяйственных культур используется доверительный интервал, который позволяет реализовывать статистическое моделирование значений матрицы ошибок. Чем выше показатели нижнего порога интервала, тем больше модели требуется совпадающих характеристик, чтобы отнести образец к определенному элементу, раннее обученной модели (рисунок 70).
Данная матрица сопоставляет предсказанные и истинные классы заболеваний растений. При этом выделяют три ключевых показателя, описывающих качество работы модели: точность (Precision), полнота (Recall) и F-мера (F-score), которые рассчитываются для каждого заболевания отдельно. Они позволяют дать более точную и объективную оценку процессу работы модели, ориентированному на распознавание конкретных типов фитопатологий.
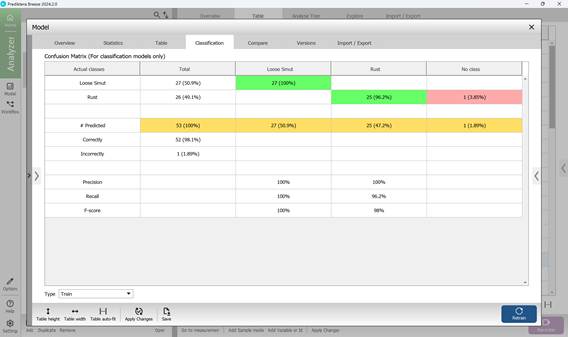
Рисунок 69 – Матрица ошибок
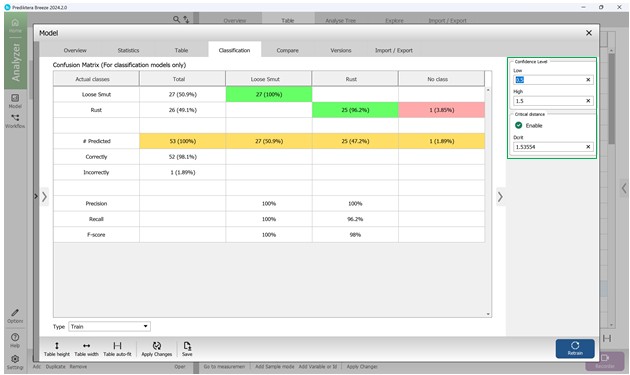
Рисунок 70 – Статистическое моделирование значений матрицы ошибок с учётом доверительного интервала
Перейдя к пятому разделу под названием «Compare» в меню «Model», можно провести сравнение ключевых статистических метрик моделей классификации (рисунок 71).
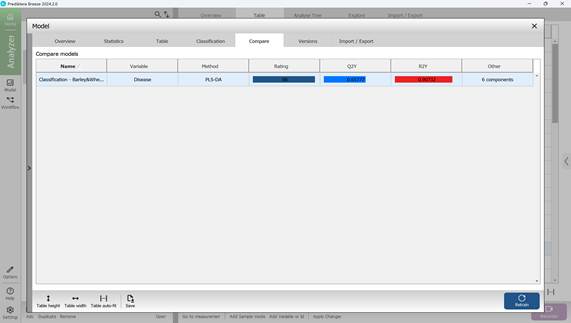
Рисунок 71 – Сравнение ключевых статистических метрик моделей классификации
Далее для выхода – закрываем меню «Model», кликнув на значок «X» в верхнем правом углу.
Обычно на всех этапах настройки большинство параметров выбираются по умолчанию, которые при необходимости можно изменить. Модель обучается на размеченных данных с известными признаками поражения, что позволяет в свою очередь в дальнейшем автоматически выявлять и классифицировать поражённые участки на новых изображениях.w